Advanced BI queries using puzzle pieces
17-7-2022
Back in 2011 our research consultancy team had collected quite a lot of interesting data for one of our clients. While previously we would put all of it in a report, print it out, and call it a day, one of my colleagues at the time proposed to make the results into an interactive dashboard instead. The client agreed – now we only needed to build a dashboard!
Now remember this was back in 2011 – the same year Internet Explorer 9 and Power BI were released. Big data was not a thing yet and most of our data collection and analysis relied on manual data wrangling in Excel. This meant that we could probably create the dashboard and prepare all the analysis in Excel just fine, but how were we going to put this on the web? We decided to contract a web development agency to develop a content management system of sorts – with special support for displaying charts based on CSVs and Highcharts.
At the time, our client was very impressed – the charts animated! Still the maintenance of such a dashboard required a lot of handwork. Meanwhile we managed to highly structure the underlying data in what became to look more and more like an actual database. Couldn’t we just upload this database to some database system and use that directly?
In 2012 I came on board fresh out of college. I had quite some knowledge of web development – HTML, PHP, MySQL and a sprinkle of JavaScript had provided me with quite a nice side job while I was still studying. At the time I was always very excited to try new technologies – NoSQL! MongoDB! – and so I quickly noticed Google Blockly, which was released in May that year. As a side project I began to hack on the dashboarding software by the end of 2012 and tried to integrate the library.
The first prototype was quickly up and running and proved to be quite interesting. For the first time, my Excel-savvy colleagues could interact with a database without having to learn the language to do so. Instead, they could drag and drop colorful puzzle pieces (which, initially at least, did require some explaining to fellow colleagues whose eyes would fall on screens showing what at first appears like a child’s game).
The system quickly converged thanks to user feedback to what it essentially still looks like today – a demo is below.
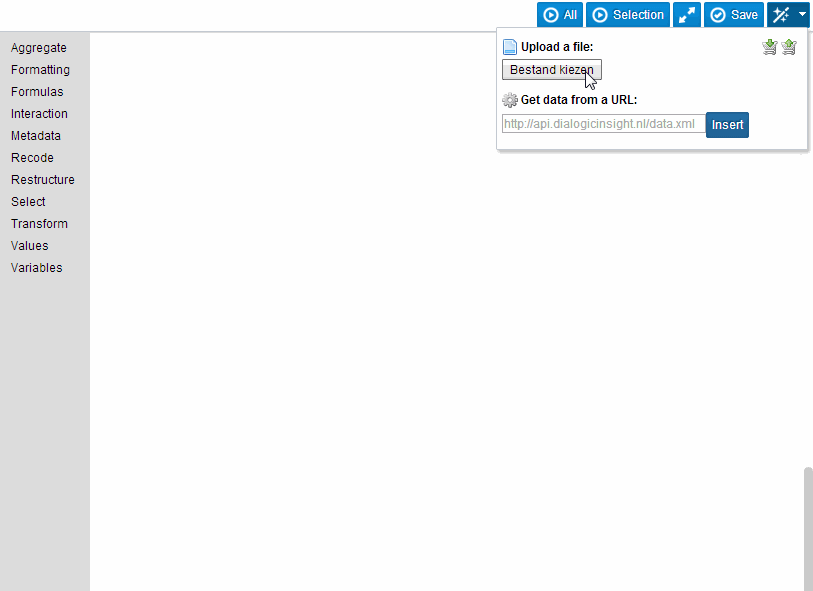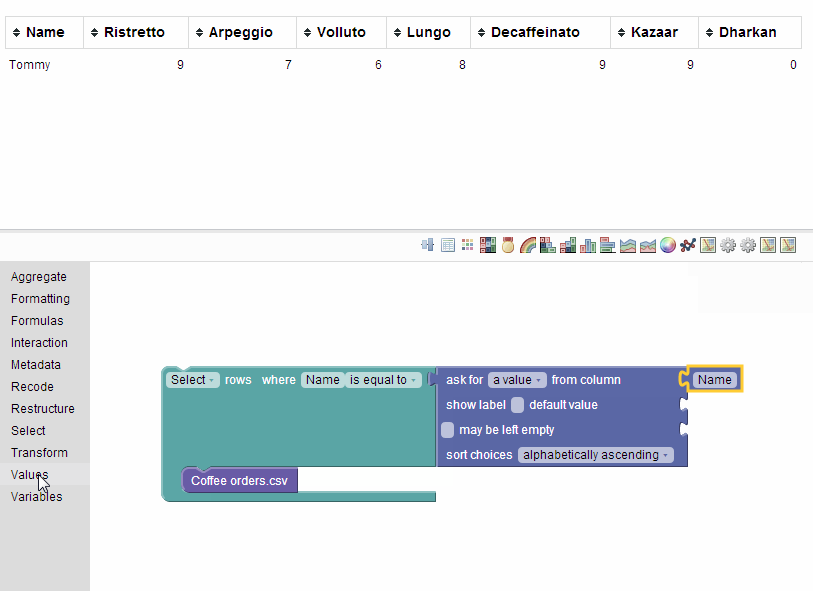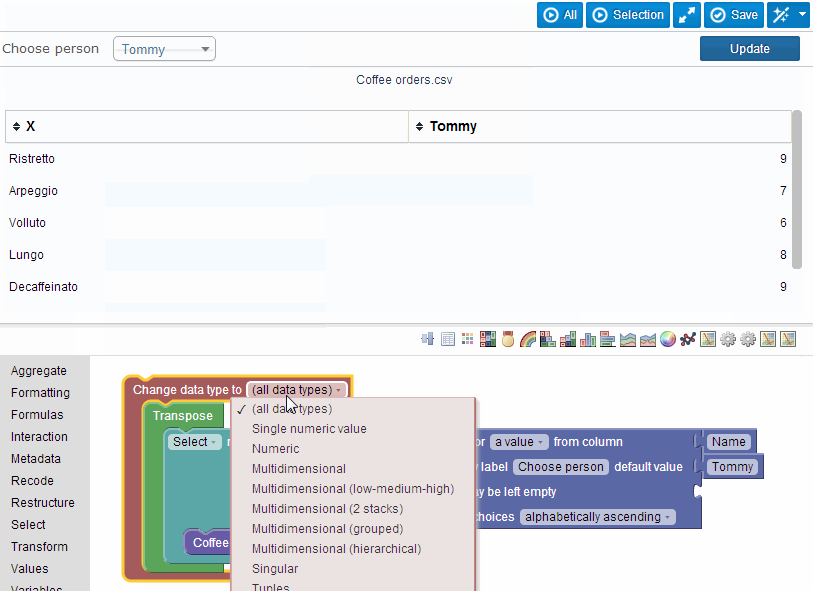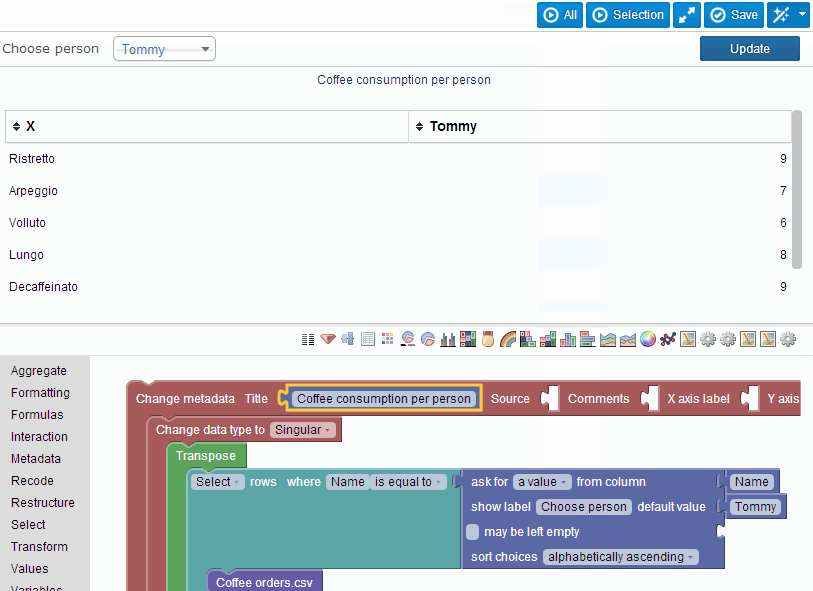
How does this work? In the blockly editor, our system injects various puzzle pieces that correspond to operations in SQL: select, order, group, et cetera. Additionally users could add new puzzle pieces representing data sources, such as a plain old CSV file or (a little later) tables in MySQL. These puzzle pieces could then be combined in a way that actually quite closely resembles relational algebra (the puzzle pieces being functions that ‘project’, ‘select’, ‘rename’, ‘join’ et cetera, taking other puzzle pieces as their inputs).
When a chart is saved, we obtain the puzzle lay-out (as XML) as well as a JSON representation of the query. This JSON more or less looks like this:
{
"op": "order",
"by": "amount",
"ascending": true,
"from": {
"op": "select",
"from": { "op": "file", "id": 1337 },
"field": "name",
"value": { "op": "const", "value": "Tommy" }
}
}Our system then takes this JSON and executes it. At first this was implemented as recursive function calls, with functions (in PHP) mapping to the different ‘ops’, e.g.:
order(select(file(1337), "name", value("Tommy")), "amount", true)The data would be passed around as plain PHP arrays-of-objects. PHP was however not very fast and at some point we had to resort to Facebook’s ‘Hip-Hop VM’ or HHVM to make this usable – fun times!).
When I wanted to add support for MySQL tables, I quickly realized that downloading all data into PHP arrays was not going to be an ideal solution. Instead, I tried to convert the ‘ops’ to SQL code so I would only have to download the actual result of the query. Additionally my queries would make use of the database’s indexes which of course is good for performance. The main issue is that of course, my colleagues didn’t care about the difference between MySQL and the good old CSV files, and the system needed to support mixing the two.
Eventually I ended up with a fairly sophisticated execution engine, that could execute parts of a ‘puzzle’ in SQL. Then, when a CSV entered the mix, it would (based on heuristics) decide to either download the intermediate result from the database (and continue in-memory) or upload the in-memory result to a temporary table in MySQL and continue in SQL (this actually proved to be the quickest way to execute e.g. joins between an SQL table and a CSV, which commonly happened). This also allowed to implemented several ops that were difficult in SQL (e.g. pivot tables – these were done partially in SQL and partially in-memory).
Finally, interactivity was added. The ‘puzzles’ could be partially executed, up to a point where user input was required. Then, the user would be asked to select values, and the puzzle would be re-executed, now with the required parameters.
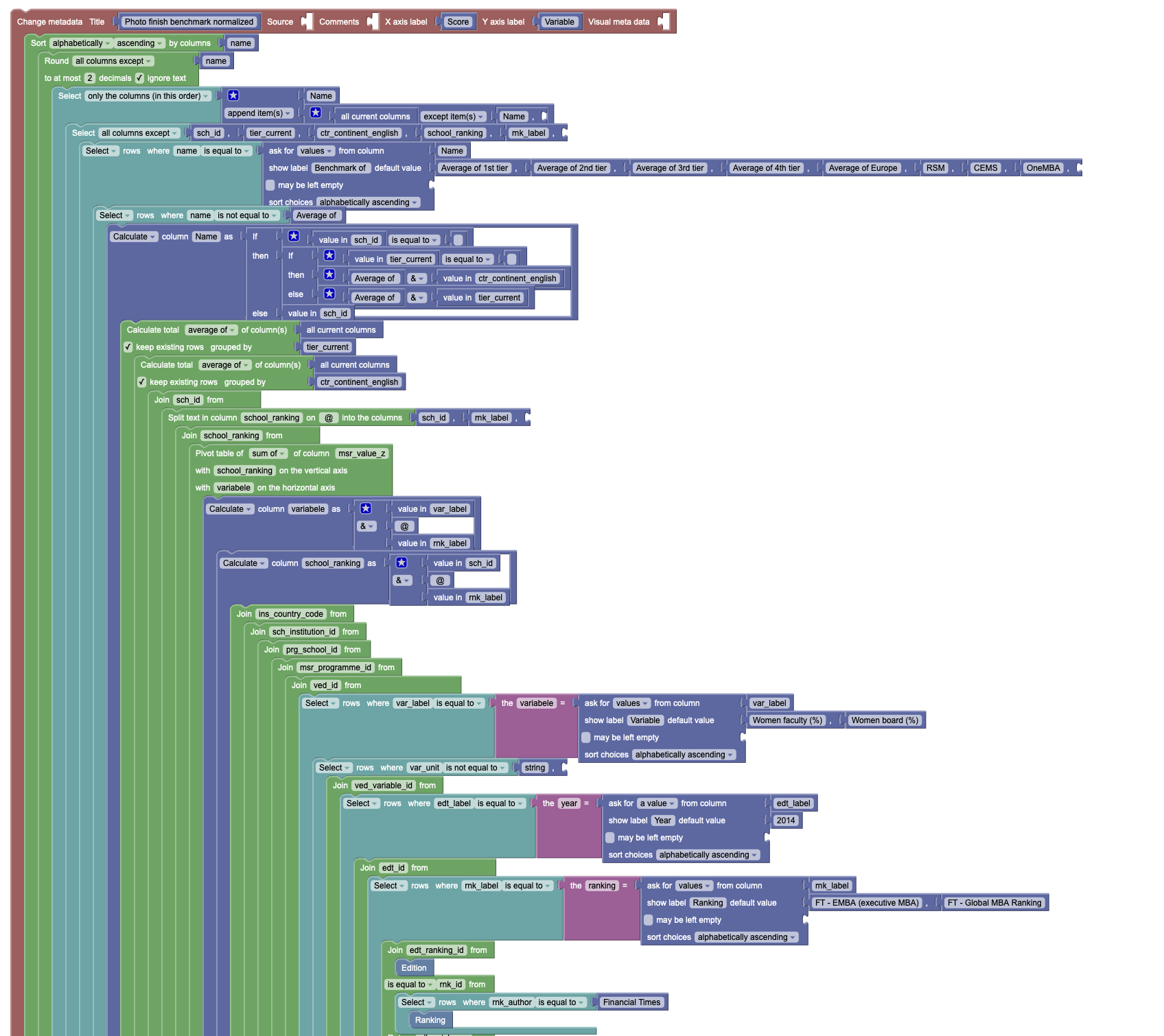
Of course my colleagues managed to find the limits of this system each and every time. Below is a picture of (the top part of) an example of a ginormous puzzle, of which there are many in the system still today.
Interestingly, many colleagues who started out with the puzzle pieces moved on to learn SQL afterwards. As time progressed, this knowledge became more widespread, and we actually hired data scientists and other people who already knew SQL. Still, to this day, the now infamous ‘puzzle pieces’ prove an invaluable tool in our projects.