Often the best way to understand something is to try and (re)build it yourself. Over the past year, I have become fascinated with machine learning models. Playing around with things like ChatGPT and Stable Diffusion is a lot of fun and a good way to get a feel for the ‘level of intelligence’ actually provided by these AIs, I like to take a peek under the hood to see what drives this magic.
One way to do this is to download one of the smaller cousins of the models mentioned earlier (e.g. something like BERT) from a platform such as HuggingFace. Loading the model file in Netron yields a large ‘map’ of the model itself. Each node in the graph represents a mathematical operation – typically involving tensors (large multi-dimensional matrices). The model can be brought to life by ‘simply’ executing each node in order, forwarding one node’s output to the next one.
The example below depicts a (small part of a) BERT-based model for ‘question answering’ – I was interested in these kinds of models specifically because hey, answering questions is actually my day job, and a model like this could be very helpful. The way a model like this works is you feed it with a text and a question (which you need to translate to ‘tokens’ – essentially numbers referring to words) and the model gives you the piece of text it thinks is most likely to contain the answer to the question.
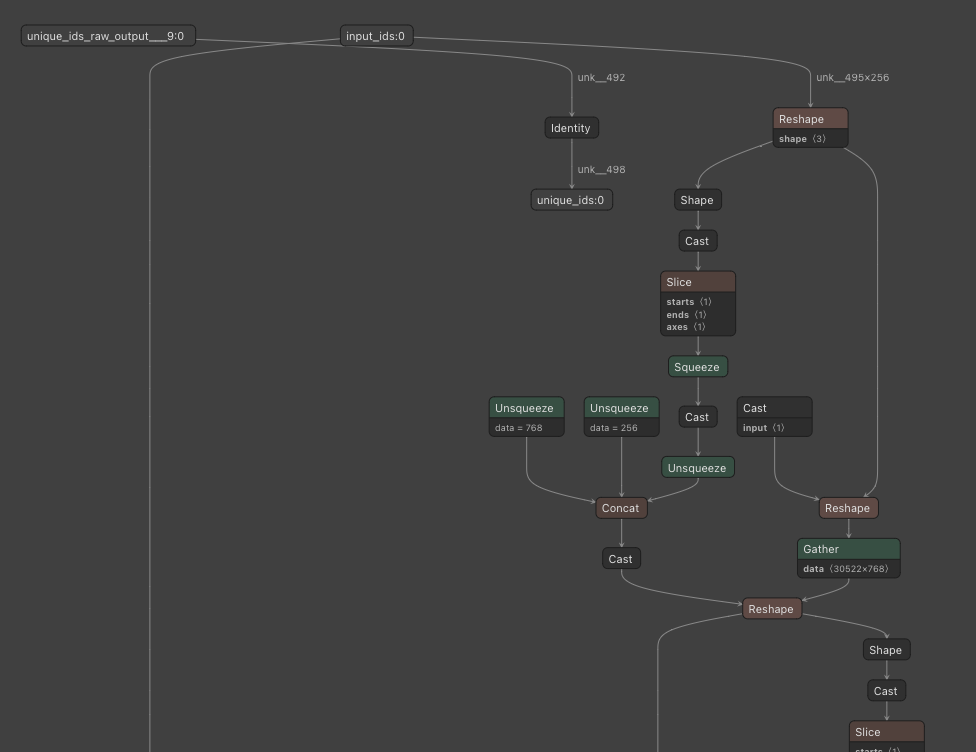
It is fairly easy to load and run a model like this from Python. This however did not really satisfy my curiosity – I wanted to be able to actually see under the hood. Also, at the time, the Python environments these models typically require did not support my hardware (an old MacBook Pro at the time).
As I was also experimenting with Rust at the time, I soon came across the wgpu library. It basically allows one to run computations on a GPU in a platform-independent way. Additionally, because both Rust and wgpu support compilation to WASM, you can actually do this from a web page thanks to the new WebGPU standard. As of today, WebGPU is still not enabled by default in the major browsers, but we might see this happening in Q2 of 2023.
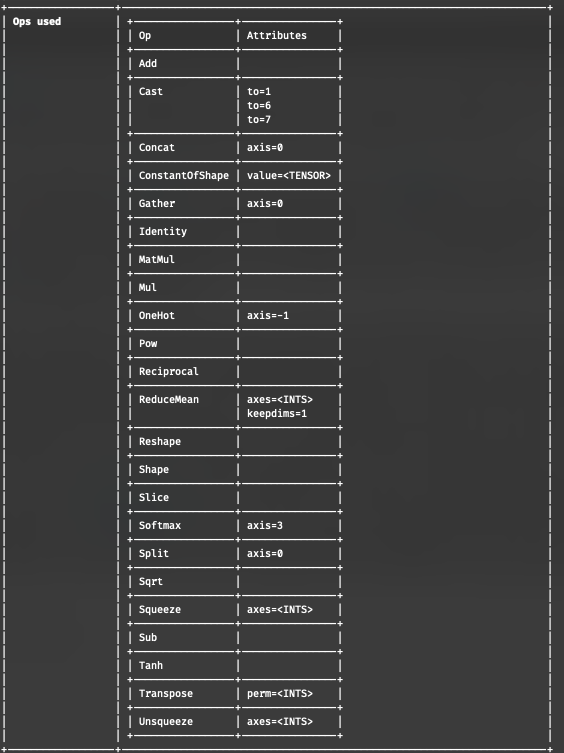
All of this made me ponder the idea of actually making an attempt at implementing the machine learning operations as GPU operations to try and run a model completely by myself, on the GPU. This of course is a very complicated undertaking. First, you’d need to obtain the models in a format readable from Rust (I stumbled upon ONNX as an interchange format, which is rather baroque but quite easy to read and work with from Rust). Second, you’d need to figure out exactly how to format a model’s inputs and outputs (this seems easy until you start to read up on tokenization schemes). I quickly decided that the latter was ‘out of scope’ (the tokenizers crate is also really easy to use). Finally, and perhaps the most important challenge, is the fact that there are simply a lot of ‘operators’ required in order to run the more interesting models. The below table shows the set of operators used in the BERT QA-model mentioned earlier, all of which would have to be implemented (and implemented exactly right) for the model to work.
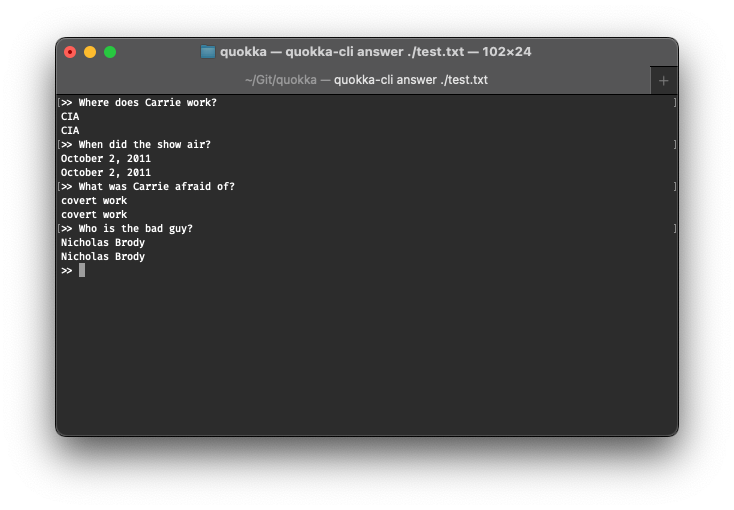
Many sunday afternoons later, the library is in fact capable of answering questions! The kick you get the moment this worked for the first time is something many programmers will probably recognize.
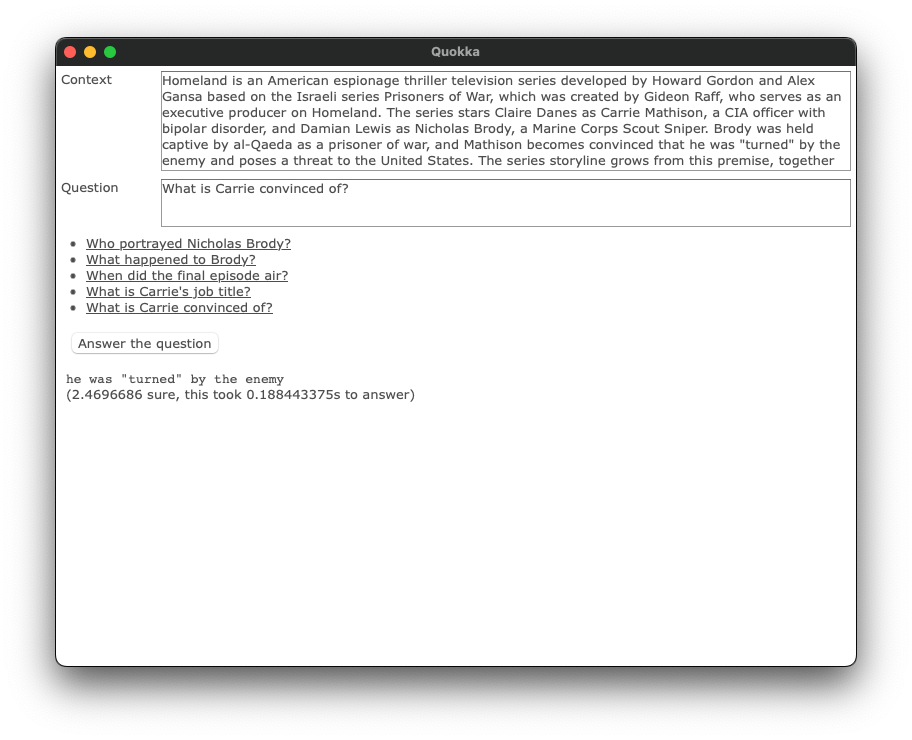
Afterwards I added many other things, such as a simple UI (based on Dioxus) and a thing called ‘shape inference’ that will allow many more models to be used in a more flexible way. My next goal would be to support multilingual and more complicated models, such as MDeBERTa. My time is limited however…
So, this project became a little bigger than anticipated – I have apparently edited more than 38k lines of code by now and am now the #1 contributor to the project. The experience of working with random strangers on the internet on a piece of software is quite fascinating and rewarding however. I learnt a lot in the process, including many quirks of GPU’s, WebGPU and async rust. As in many cases, it’s not the destination, but the journey that really matters.
Link: WebONNX: WONNX on GitHub
Try it yourself: (faster than..) real-time image classification with SqueezeNet in the browser (use Chrome Canary and enable WebGPU through configuration flags)