Warp 2.0: Link big data sets by drawing arrows, and more
2-6-2015
In the past two months I’ve been working hard on Warp 2.0. Warp is the swiss-army knife of big data, allowing you to handle big data sets with the same ease as a spreadsheet file. Warp enables this by providing an intuitive interface (‘query by example’) and by performing its data operations as fast as possible.
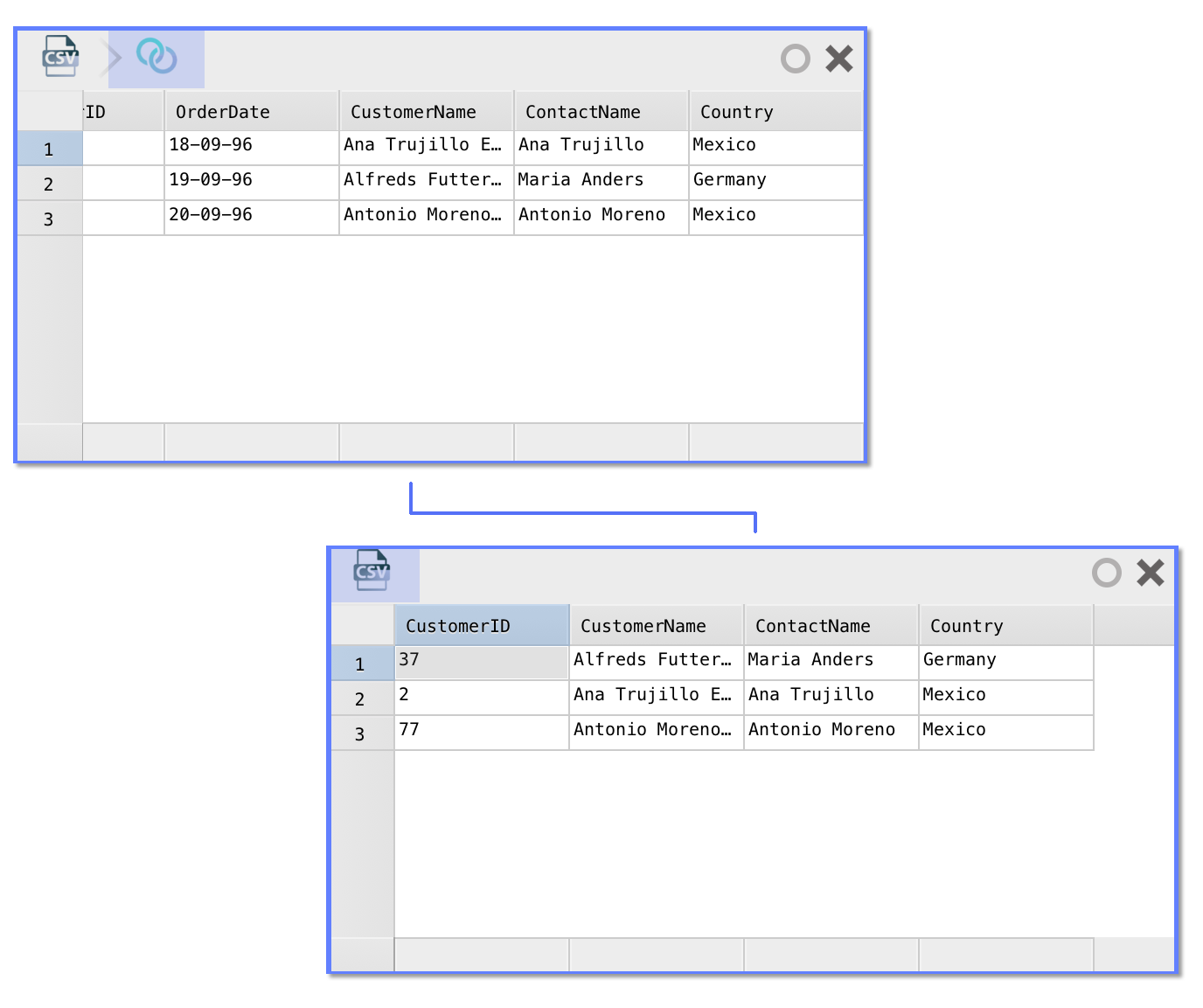
Join data sets by dragging an arrow
In Warp 2.0, the user interface has been completely overhauled. You can now work with more than just one data set at a time. Each data set is represented as a ‘card’. It borrows a page from the Interface Builder book: joining data from one data set to the other is as easy as (literally) ‘drawing an arrow’ from one card to the other. This is perhaps best demonstrated in the animation below.
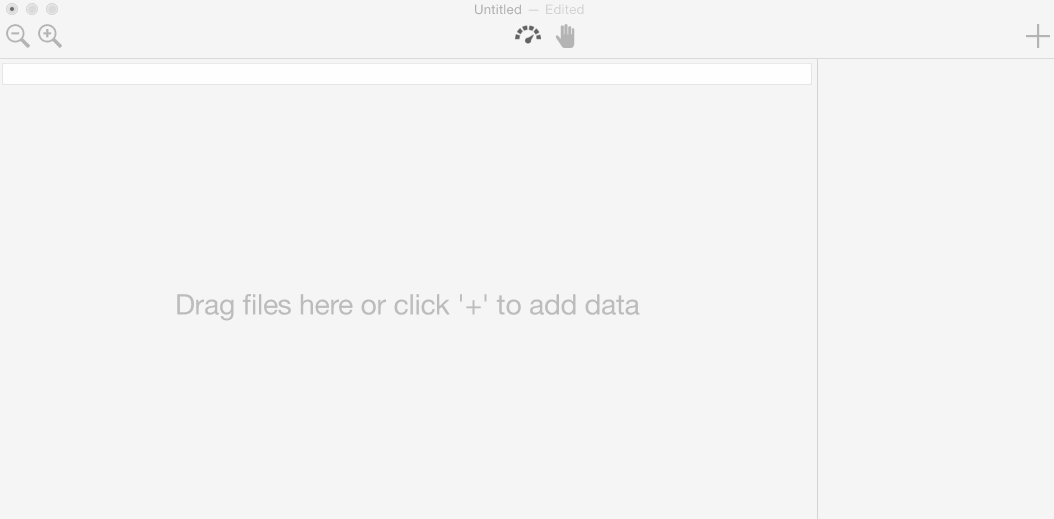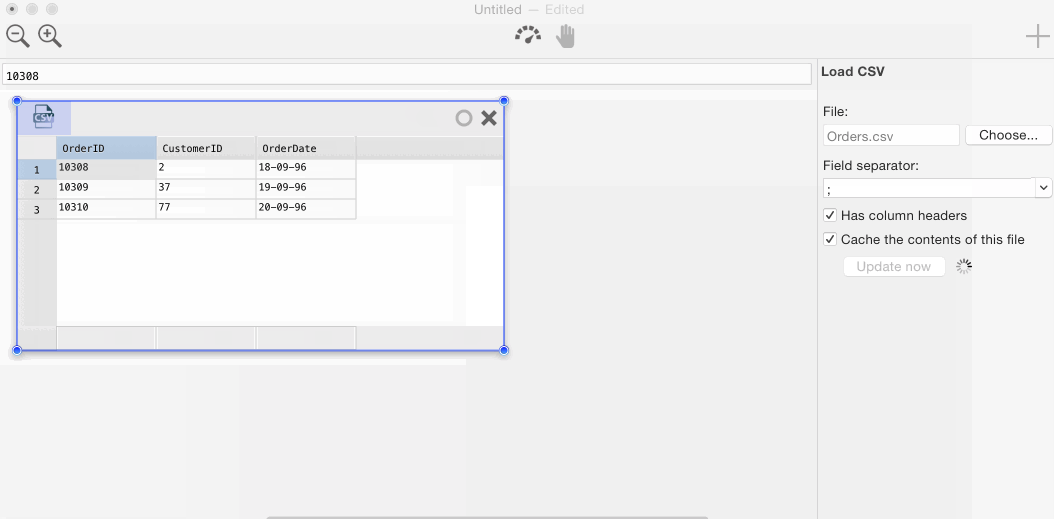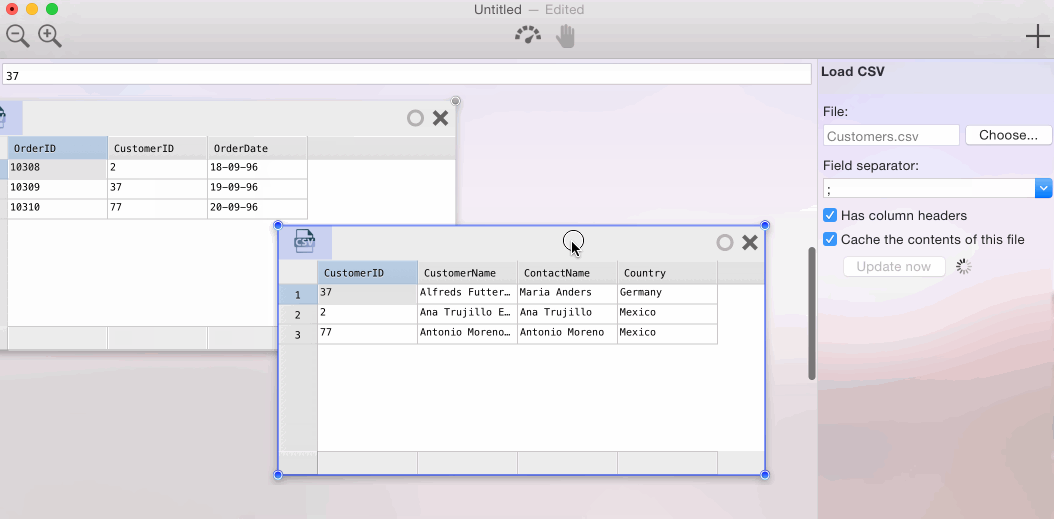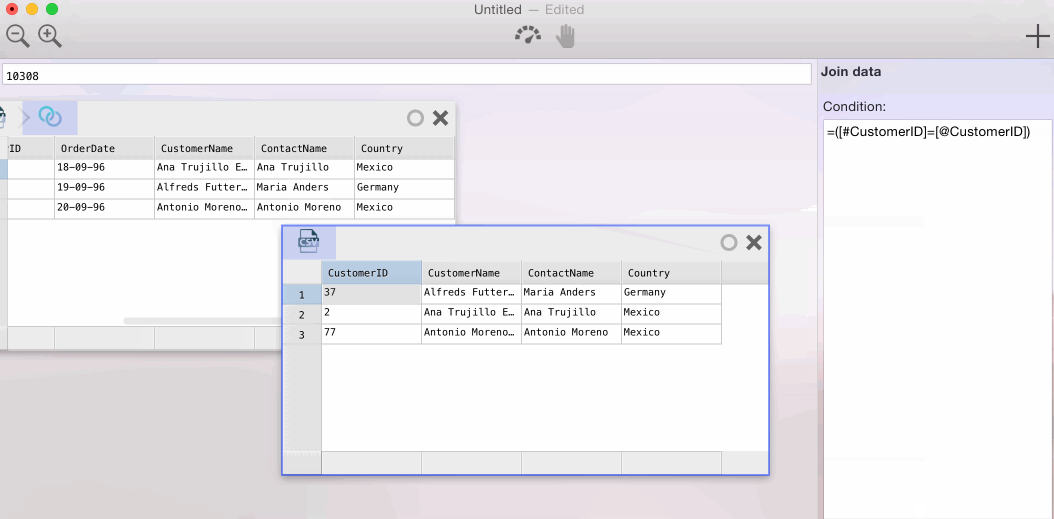
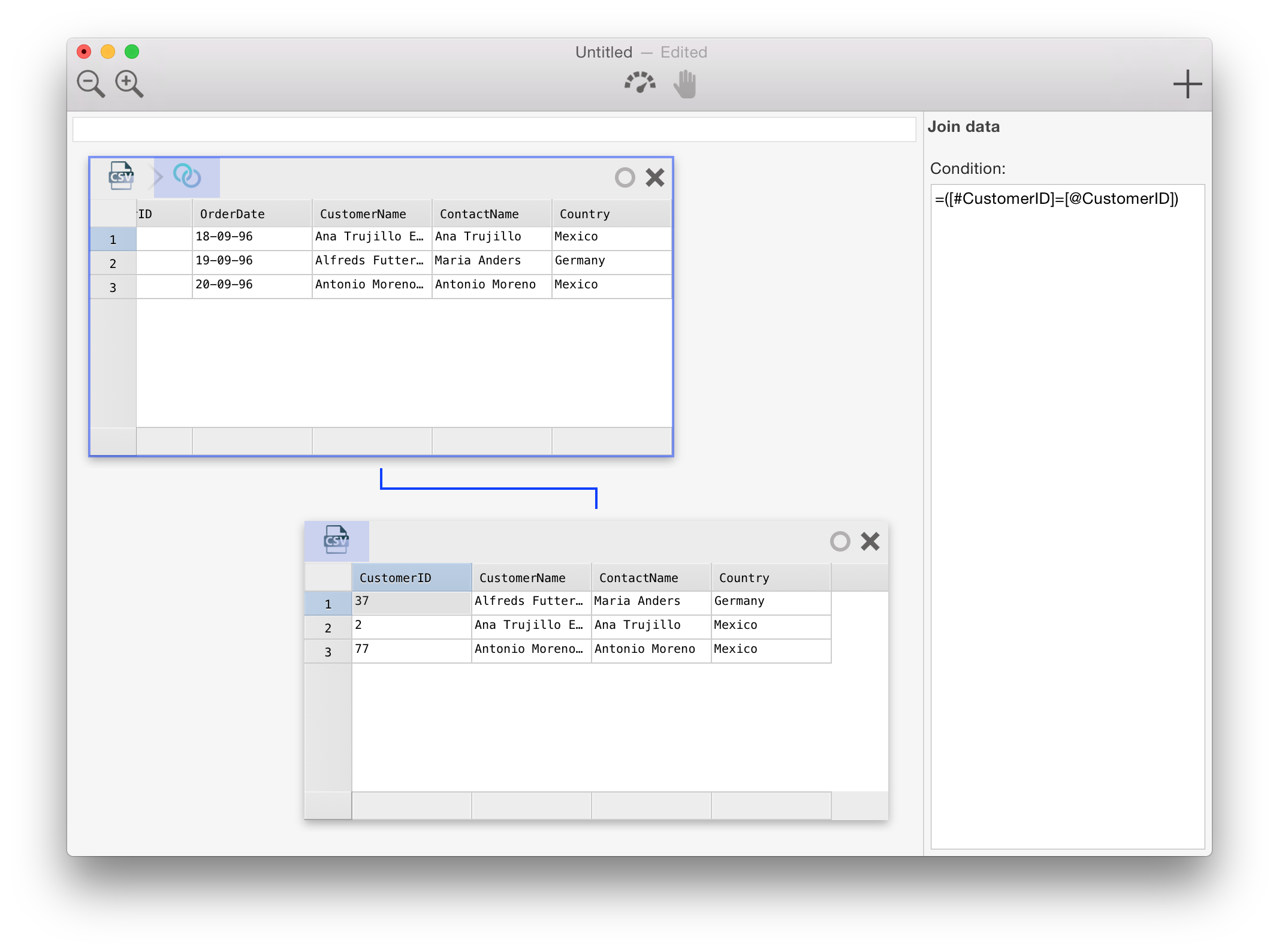{kind=link}
The join trick works regardless of the source the data of either card comes from. In the worst case, Warp will have to download data from both data sources. More commonly, Warp can perform the join in the source database (e.g. if the two cards come from the same server/database) or can join a smaller table to a (very) large table by uploading the smaller one as a temporary table. In upcoming releases, even smarter algorithms will be added that allows cross-database joins without fetching full data sets.
Data sets are still represented as a table, on which various analysis steps can be performed (and are automatically ‘recorded’ based on what you do) – a bit like Excel’s Flash Fill on steroids.
SQL optimized execution (‘query pushdown’)
The performance of a calculation is always either bound by processing, storage or communication limits. Warp optimizes execution of queries in each of the three dimensions. Optimizations in Warp happen at several layers:
- At the top level, Warp helps the user when defining the desired calculation. Redundant ‘steps’ are automatically removed or coalesced.
- Each step generates a series of ‘data commands’. Data commands are coalesced as well (e.g. a ‘rename column A=>B’ followed by a ‘rename column B=>C’ is merged to a single ‘rename column A=>C’).
- Static optimizations are performed on each coalesced data command (e.g. expressions are short-cut, constant expressions are pre-computed, et cetera)
- Depending on the data set and underlying data storage mechanism, further optimizations may be possible. For SQL back-ends, many operations can be combined in a single query.
- If multiple different types of data sets are to be combined, Warp attempts to find a method that allows for the most efficient computation (e.g. if two SQLite data sets are to be joined, Warp will make sure the join happens fully in SQLite).
One particularly important optimization is to ensure calculations happen ‘close’ to the place where the data is stored. This prevents excessive use of I/O or even network bandwidth. It also allows optimizations at the lowest level (after all, each piece of data that does not have to be read from disk is not stored in memory, not transferred over the wire, and as such performance increases through the whole chain). Another benefit is that this allows Warp queries to make use of any parallelism that might exist at the storage layer (e.g. database clusters).
In this release, many improvements were made to an optimization called ‘query pushdown’. Query pushdown is the mechanism through which Warp attempts to delegate calculations to the data source(s) data is pulled from. If you ask Warp for a random selection of rows from a very large table, Warp will not fetch the full table and then make the selection, but will ask the database that stores the table for a random set of rows. Query pushdown requires Warp to ‘speak’ the language of these databases (e.g. SQL and all its dialects). It is imperative that queries that are ‘pushed down’ deliver are equivalent to results calculated ‘in-memory’; this is a difficult problem to solve because databases differ greatly in their type systems, available functions, error handling, et cetera. In Warp, query pushdown is now supported for MySQL, PostgreSQL, SQLite and Facebook Presto.
PostgreSQL
As of Warp 2.0, Warp supports PostgreSQL as data source. Warp can connect to PostgreSQL databases and translate about 90% of all data operations to high-performance SQL, which can be directly executed in the database (near the data).
Improved formulas
Thee formula language in Warp has been improved to make working with strings easier than ever.
- Using the SPLIT function, you can split a string in pieces; you can use it in conjunction with the NTH function to grab a particular piece (for example, =NTH(SPLIT(“Hello world”, ” “), 1) will result in”Hello”).
- Support for regular expressions has been added, which is a language used to describe the format of a string and can be used to test whether a certain text matches that format or not. Use the ‘±=’ operator to match texts, like so: =”3514AX”±=”[0-9]+[A-Z]+”. By default, the regular expression matching is case-insensitive; use the ‘±±=’ operator to make it case-sensitive.
- You can now use the LEVENSHTEIN function to calculate the ‘difference’ between two texts. The number returned by the Levenshtein function is the number of ‘edits’ required to transform the first string to the second, also known als the Levenshtein distance.
Note that in many cases, you do not have to type formulas at all: just type the desired result in a table cell, and Warp will try to find a formula that calculates that strings for the other cells automatically.
Think big, work small
 Since the beginning, one of the core principles in Warp is that you can design an analysis operation on a smaller data set, and then run it easily on the full data set. This allows you to work fast and makes it possible to experiment. Warp 2.0, includes a statistical engine that decides how big exactly the ‘working set’ should be. If you use data from a ‘slow’ source or use complex analysis steps, the data set will be smaller. You can configure the maximum size as well as the maximum time Warp is allowed to take to calculate the working set calculations in the settings window.
Since the beginning, one of the core principles in Warp is that you can design an analysis operation on a smaller data set, and then run it easily on the full data set. This allows you to work fast and makes it possible to experiment. Warp 2.0, includes a statistical engine that decides how big exactly the ‘working set’ should be. If you use data from a ‘slow’ source or use complex analysis steps, the data set will be smaller. You can configure the maximum size as well as the maximum time Warp is allowed to take to calculate the working set calculations in the settings window.
What’s next?
The next version of Warp will incorporate exciting functionality to make it the spreadsheet of the big data era. Stay tuned for updates!
Get started now
Warp 2.0 can, as usual, be downloaded from the App Store. Feel free to let us know if you have any suggestions or ideas about Warp. Download Warp 2.0